本笔记主要记录今日的hugging face 推荐的arxiv文章以及alphaXiv上推荐的几篇文章,都是和自监督相关的文章内容。
1 DINO v3,一种自监督的视觉基础模型
ref: O. Siméoni et al., DINOv3 (2025), , doi:10.48550/arXiv.2508.10104.
这一模型在计算机视觉的诸多任务上有着不错的表现,其在训练过程中引入了一种新的方法 Gram anchoring,其能够有效的解决训练过程中的dense feature maps degrading(退化)的问题。
首先是线性探测结果,DINO要比传统的WSL算法提示20个点以上:
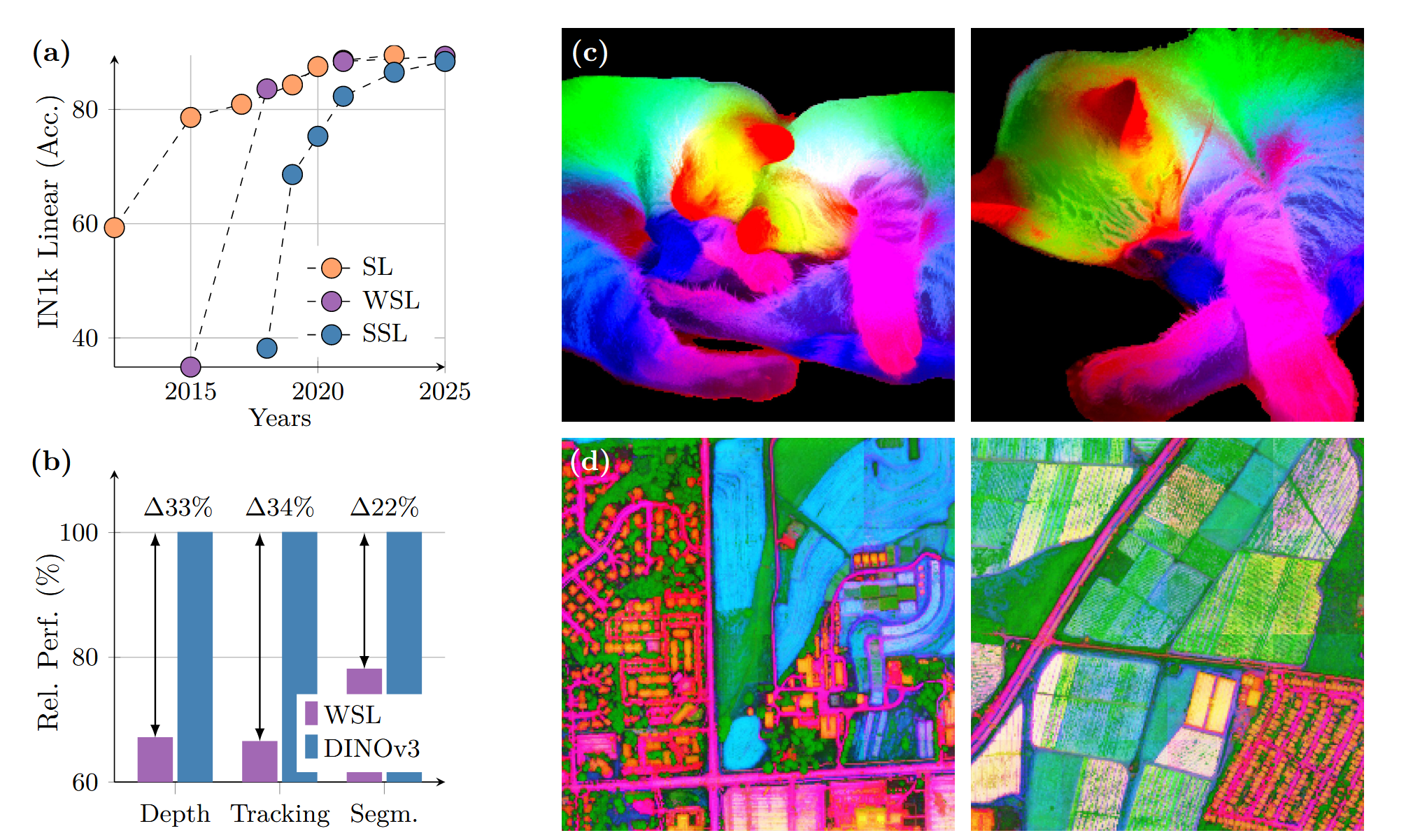
且相同的计算开销下,DINO网络的准确性更高(功耗低):
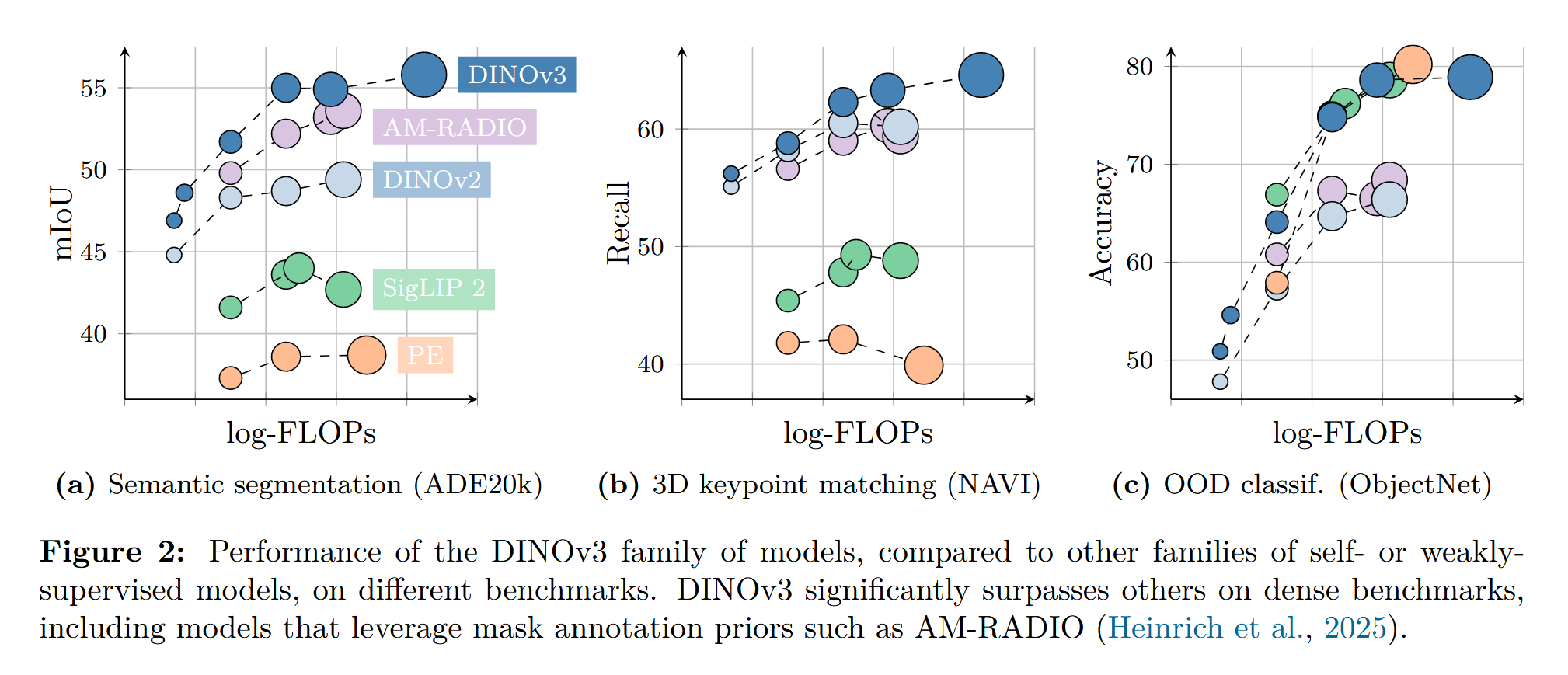
比较震惊的是,DINO网络可以比较好的理解你的标记并找出与你标记接近的图像中的同类,如下图所示:

不难发现,以左下角的橘子为例,红十字选中的句子,于是在dense feature fig中,DINO将符合橘子形状颜色特征的以绿色标出,其中越接近则颜色越明显。其他水果亦然。
但是,随着迭代次数的增加,一般情况下,dense feature fig会逐渐产生失真:
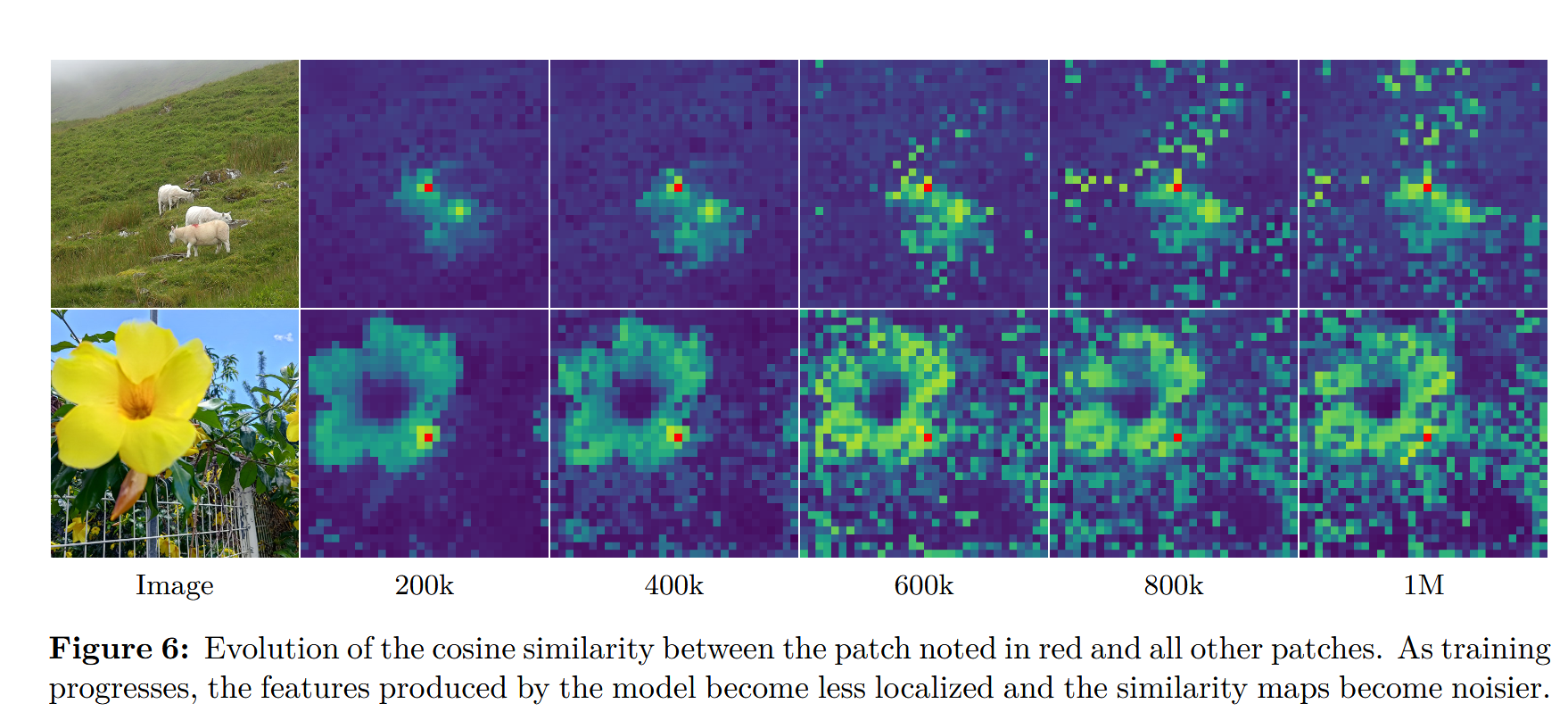
该文章引入了一个gram的方式来避免多次迭代导致的特征图失真:
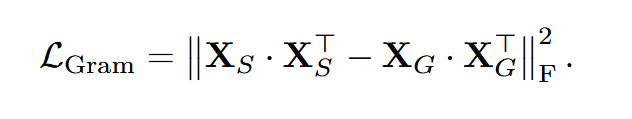
通过将前面训练的模型作为教师模型,把刚训练完的模型作为学生模型,两者对比学习,类似于知识蒸馏,以便于能够保留住前面模型在dense feature fig上的优良表现。
DINO网络不仅仅可以用于获得dense feature fig,还能够用于视频的segmentation tracking以及遥感数据分辨的提升
2 多视角3D点跟踪
ref: F. Rajič et al., Multi-view 3D point tracking (2025), , doi:10.48550/arXiv.2508.21060.
据作者说是首个数据驱动的3d多角度点追踪算法,这一算法可以较好的解决传统的单视角点追踪下的遮挡和模糊的问题,同时相较于其他的多角度追踪算法而言,该算法需要的相机数量更少(4个即可)
整个网络的结构如下图所示:
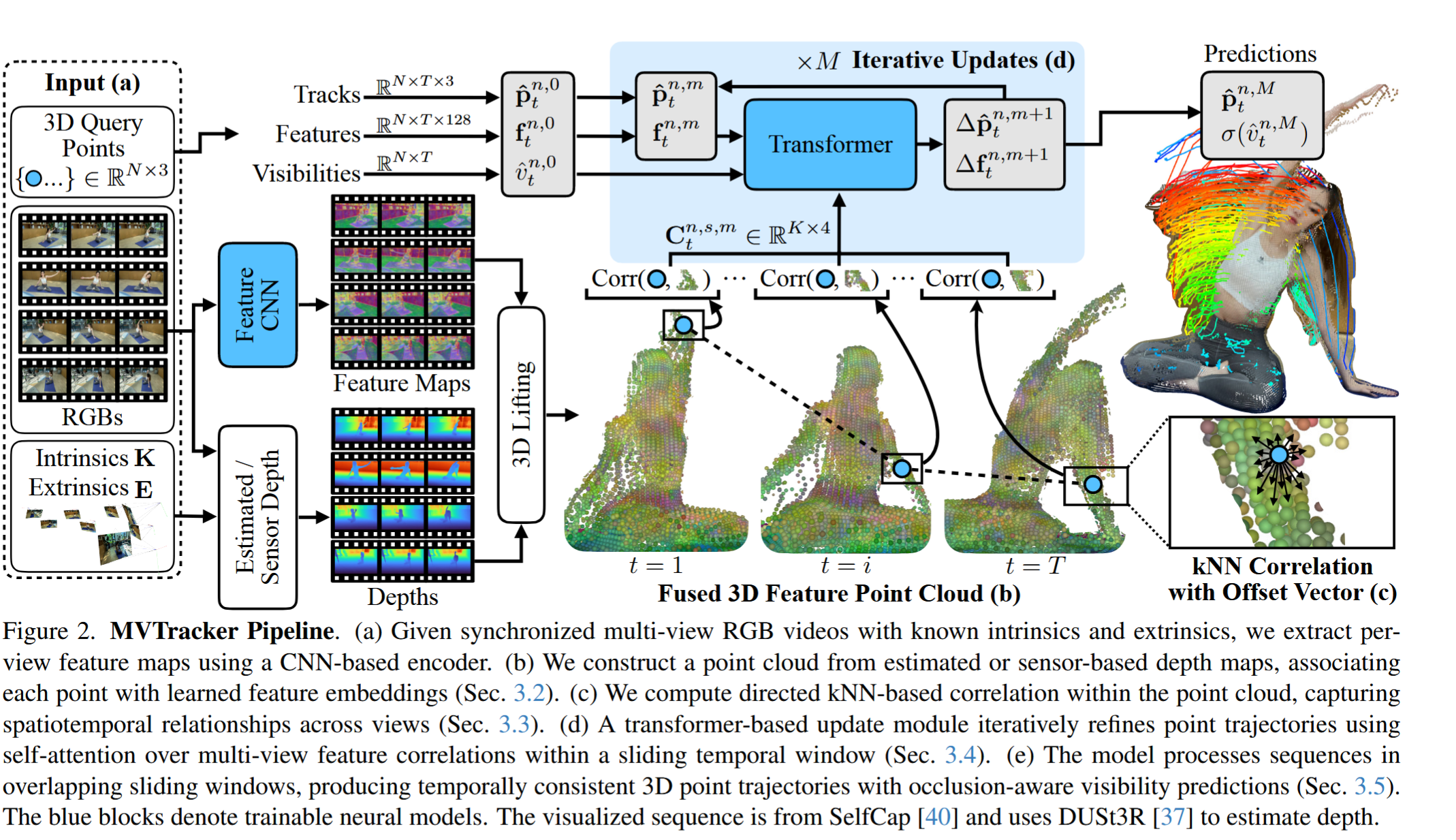
可以看到,这里的网路输入总共有3个,一个是需要追踪的点(也就是query points),还有就是正常的多角度的视频图像信息(对应图片中的RGBs),最后的内参Instrinsics和外参Extrinsics则是相机的参数以及方位等信息。
对于图像信息可以直接通过特征提取的CNN获取特征图feature maps,然后将图像信息和内外惨信息结合就可以得到深度信息,将特征信息和深度信息结合得到3d的特征点云,再通过KNN想关心学习查询点附近的其余点特征来预测点轨迹
 可以看到,该算法相较于其他的追踪算法而言,准确率更为优异
可以看到,该算法相较于其他的追踪算法而言,准确率更为优异
3 STOXLSTM: 一种用于时间序列预测的随机扩展长短期记忆网络
ref: Z. Wang, Y. Li, L. Zan, Z. Gong, M. Zhu, StoxLSTM: A stochastic extended long short-term memory network for time series forecasting (2025), , doi:10.48550/arXiv.2509.01187.
在此之前,我们先回顾一下最平常的lstm模型:
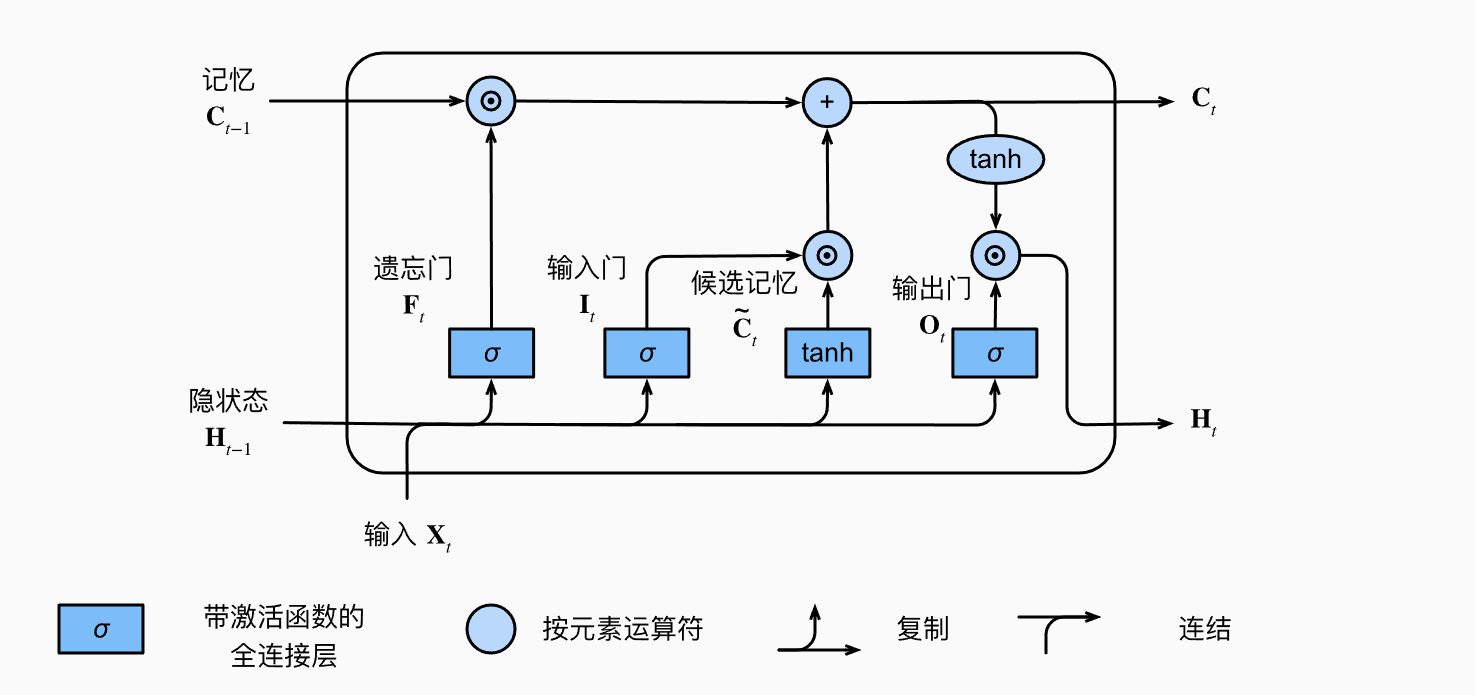
首先,当前时刻的输入和上一时刻的隐藏状态做sigmoid得到遗忘、输入门、输出门三个,做tanh得到候选记忆备选项。将遗忘门结果和上一时刻的记忆项作用,将输入门和候选记忆备选项作用得到候选记忆,与上一时刻的记忆与遗忘门作用后的结果进行作用,进而得到当下时刻的记忆。顺便在将当下时刻的记忆和输出门作用得到当下时刻的隐状态。
而xlstm则是在此基础上增加了mlstm和slstm两种单元:
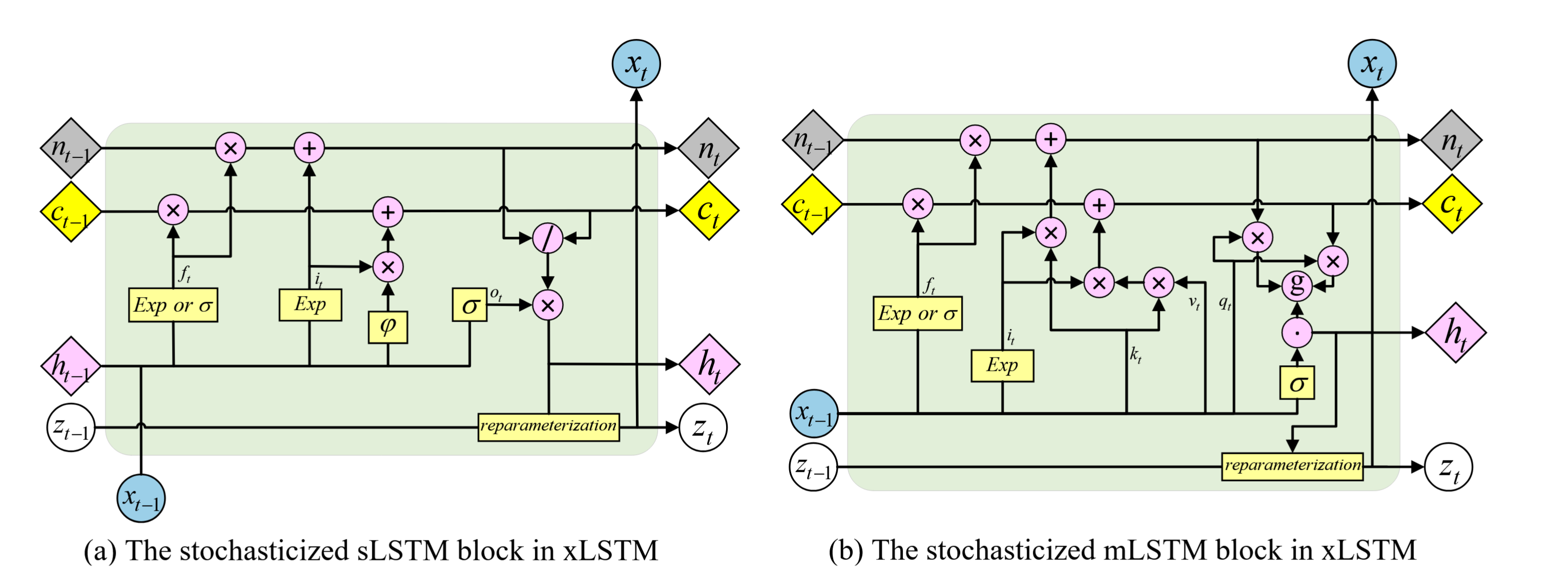
都是引入了指数来取代原先的直接sigmoid,同时引入了协方差矩阵于mlstm来辅助更新隐变量和记忆项
相应的,对xLSTM进行改进的StoxLSTM也是分别对sLSTM和mLSTM进行了改进,引入了随机性:

这里的随机性通过隐特征变量$z_t$是一个正态分布来实现